
S3LDBO: Algoritmo de bucle único con instantáneas para optimización descentralizada
Descubre S3LDBO, algoritmo de optimización bilevel descentralizada que reduce cómputo con instantáneas, mejorando eficiencia en redes de IA.
Descubre S3LDBO, algoritmo de optimización bilevel descentralizada que reduce cómputo con instantáneas, mejorando eficiencia en redes de IA.
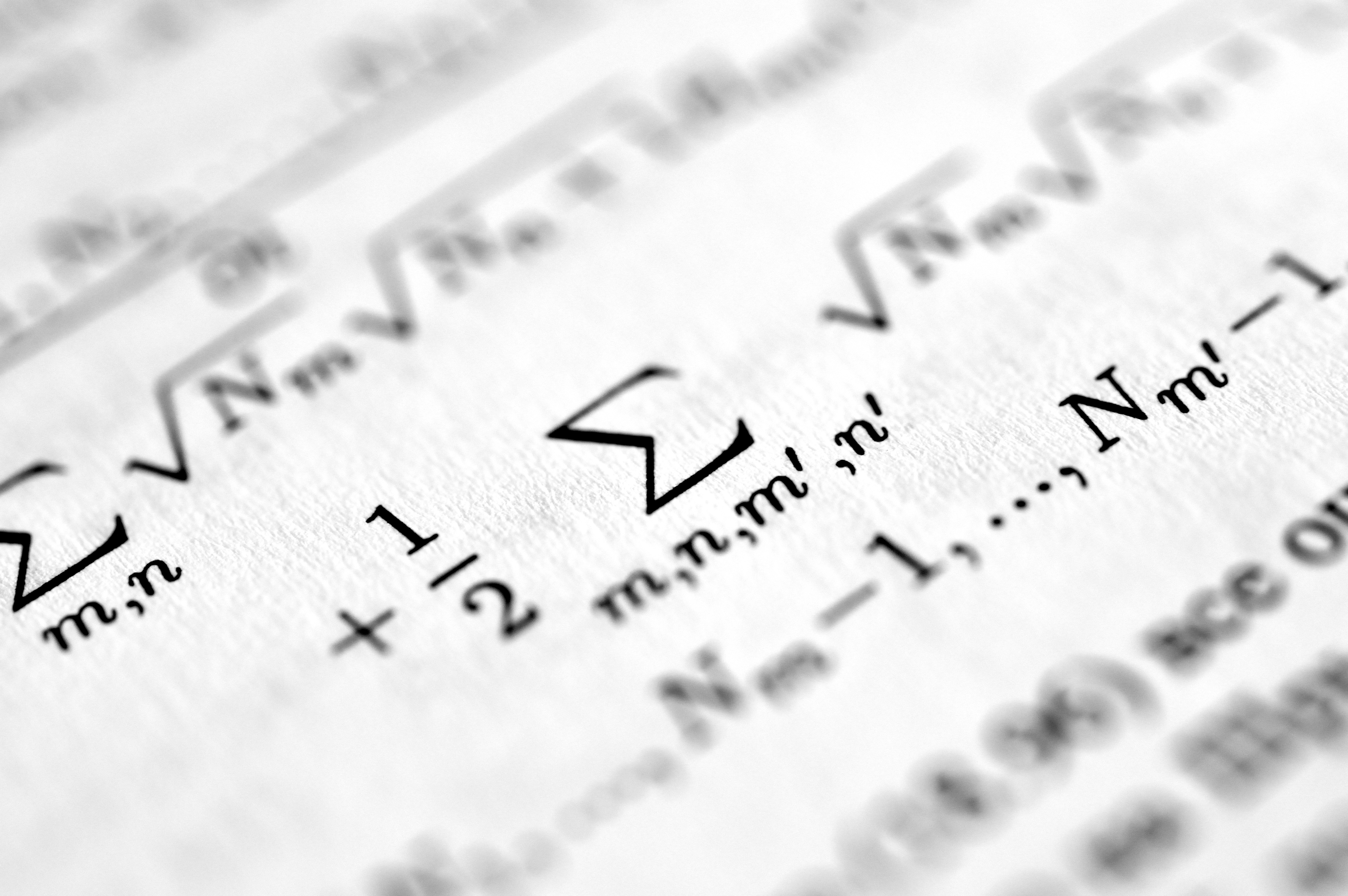
OddSHAP revoluciona la estimación de valores Shapley. Al aislar el componente impar, logra una precisión superior en atribución de ML. Descubre el nuevo benchmark.

Descubre cómo los modelos pequeños mejoran la diversidad en GRPO y entrenan modelos grandes con mayor eficiencia. Aumenta el rendimiento en razonamiento matemático.

ConMoE: consolidación de grupos de expertos con reasignación de prototipos para compresión de MoE. Descubre cómo comprimir modelos MoE optimizando eficiencia y rendimiento.

Gestión eficiente de memoria latente con destilación de contexto para optimizar el rendimiento y reducir costos.
<meta name=description content=BlockBatch optimiza la inferencia en modelos de difusión mediante consenso multi-escala, logrando mayor eficiencia y velocidad sin sacrificar calidad.>
OccamToken: poda de tokens sin entrenamiento y adaptativa al presupuesto para VLM. Reduce costos computacionales manteniendo precisión.
Poda asimétrica de tokens para inferencia eficiente en VLM. Acelera modelos de visión-lenguaje sin sacrificar precisión. Técnica optimizada.
AgentDropoutV2 optimiza el flujo en sistemas multiagente con poda en tiempo de prueba. Mejora eficiencia y rendimiento en IA distribuida.
BioArc ofrece arquitecturas neuronales óptimas para modelos biológicos. Acelera simulaciones y mejora precisión en investigación.
Optimización del modelado afectivo con recursos limitados mediante poda de regularización de varianza. Técnica eficiente para reducir costos computacionales manteniendo precisión.

<meta name=description content=Predice impactos industriales con aprendizaje de operadores geométrico y atención eficiente. Modelo innovador para análisis preciso y rápido en entornos complejos.>
<meta content=Descubre cómo paralelizar el entrenamiento de redes neuronales de picos con precisión temporal para acelerar el aprendizaje sin perder exactitud. Ideal para investigación en neurocomputación y eficiencia computacional.>

SelfJudge acelera la decodificación especulativa mediante verificación autosupervisada, logrando inferencia más rápida en modelos de lenguaje sin sacrificar precisión.

<meta content=EAGer es un método de generación consciente de entropía para escalado adaptativo en inferencia, optimizando eficiencia y rendimiento en modelos de IA.>
<meta name=description content=Inferencia Conformal con Adaptación Estructural para Pruebas Fuera de Distribución a Gran Escala - Descubre cómo esta técnica mejora robustez y eficiencia en modelos predictivos a gran escala>